Extracting the Stagecoach App's Word of the Day
Posted on 7th March 2024 at 16:22
A dive into Stagecoach's mobile app and extracting encrypted data relating to their ticketing system
Contents
Where This Started
I rely on my cities bus services to get me around, one of which is Stagecoach. But I noticed something interesting with their ticketing system. When I bought a ticket via their app, it had a QR code on it, makes sense - scan that on the bus.
But no actually, there’s no scanner on the buses here. So you end up just showing the driver your ticket. A ticket which has this spinning graphic with a different word on it every day and the current time, which I can only assume is what they’re checking, as to make sure it’s not just a screenshot or something.
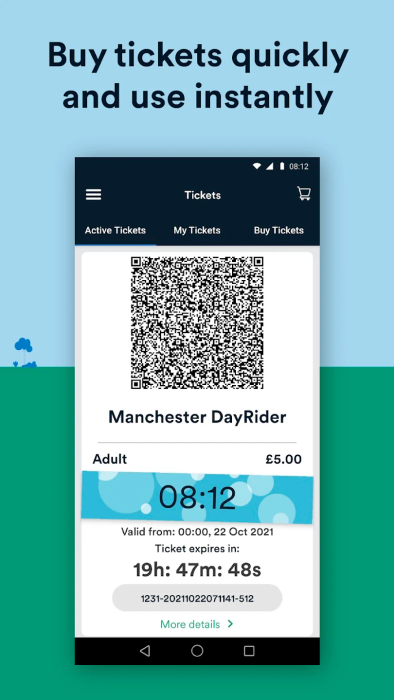
This made me curious, where were they getting this word from? Was it just some plain array in the app or retrieved from a remote server you need authentication for.
Decompiling the App
This part is pretty easy, plenty of tools exist to do this for you. I chose to use jadx as it seemed the most popular.
I grabbed the apk off of an apk mirroring site and loaded it into jadx.
But what am I even looking for? I tried searching the word for today which is prize but that yielded nothing. I then remembered that the ticket screen has some
paragraph about reporting missing people, so I search for some text from that and found a resource defining strings.
<string name="minutes">minutes</string><string name="miss">Miss</string><string name="missing_people">Missing People</string>With this I searched for the name of the string and found AbstractQrActiveTicketView, the view used for showing tickets, which is where the word of the day should be displayed.
First thing I scan through is the imports and class fields, perhaps there’s some class that the words are retrieved from.
A database model called Word catches my eye.
import com.stagecoach.core.cache.SecureUserInfoManager;import com.stagecoach.core.model.database.word.Word;import com.stagecoach.core.model.secureapi.DynamicSettingsResponse;Jumping into this file reveals this is what we we’re looking for, the class fields of day, word and colour make sense. Time to check the usages.
public class Word { private String colour; private int day; private String word;One if its usages leads to a class simply named DatabaseProvider and gives us this critical line of code.
new Gson().parse(this.AES.decryptJsonWithKey(new WordOfTheDayFile().getBytesArray(), this.secureUserInfoManager.getGeneratedKey())So this is where the words come from, figure out to how to decrypt these bytes and we’ve got them.
The Word of the Day File
The WordOfTheDayFile class is simply a class that contains a series of static classes with a single field in each containing an array of bytes, presumably the words in json format.
public class WordOfTheDayFile { public final byte[] bytes = {...};
public static class WordOfTheDayFile0 { final byte[] bytes = {...};
WordOfTheDayFile0() { } }With a method that writes them all into a single byte array.
public byte[] getBytesArray() throws IOException { ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(27000); byteArrayOutputStream.write(this.bytes); byteArrayOutputStream.write(new WordOfTheDayFile0().bytes); byteArrayOutputStream.write(new WordOfTheDayFile1().bytes); byteArrayOutputStream.write(new WordOfTheDayFile2().bytes); byteArrayOutputStream.write(new WordOfTheDayFile3().bytes); byteArrayOutputStream.write(new WordOfTheDayFile4().bytes); byteArrayOutputStream.write(new WordOfTheDayFile5().bytes); byteArrayOutputStream.write(new WordOfTheDayFile6().bytes); byteArrayOutputStream.write(new WordOfTheDayFile7().bytes); return byteArrayOutputStream.toByteArray();}This seems like a weird way of doing this, not sure if this is some weird decompilation artifact or what.
The getGeneratedKey Function
Initially the name of this function worried me, there are so many ways this key could be generated, this might just end here. Thankfully, it didn’t.
This function calls a function called unhide on the class HidingUtils. It passes a base64 encoded string to this unhide function.
public byte[] getGeneratedKey() { return new HidingUtils().unhide("<key>").getBytes();}This unhide function is actually a native Java function, meaning it’s using the Java Native Interface (JNI) to call a shared native library.
Which is loaded further up in the class. The native library is called ticket-ref-code.
public class HidingUtils { private static final String TAG = "HidingUtil";
static { System.loadLibrary("ticket-ref-code"); }
static String[] generateKeyXorParts(String str) {...}
public native String unhide(String str);}So, they’re doing this “unhiding” logic within a native library, most likely c++. This is probably to make extracting these secrets harder/take more time.
We can find the location of this native library in the resources/lib folder, let’s dig into that.
Decompiling ticket-ref-code.so
I’m not a C++ developer. I’m also not terribly experienced with reverse engineering decompiled C++ code. So that’s why I called upon my partner Emma who is more familiar to help me with this part. This wouldn’t of been possible without them.
One thing I do know about C++ decompiling/reverse engineering is that Ghidra exists and that I should use that. After trekking on a journey to download JDK 17 I was ready to get going.
void Java_com_lagoru_jnirealm_HidingUtils_unhide(long *param_1,undefined8 param_2,undefined8 param_3)
{ undefined8 uVar1; ulong uVar2; byte *pbVar3; long in_FS_OFFSET; byte local_358 [272]; byte local_248 [272]; byte local_138; byte abStack_137 [263]; long local_30;
pbVar3 = local_358; local_30 = *(long *)(in_FS_OFFSET + 0x28); uVar1 = (**(code **)(*param_1 + 0x548))(param_1,param_3,0); memset(&local_138,0,0x101); memset(local_248,0,0x101); Base64Decode(uVar1,&local_138,0x100); Base64Decode("...",local_248,0x100); memset(local_358,0,0x101); if (local_138 != 0) { uVar2 = 0; do { local_358[uVar2] = local_138 ^ local_248[uVar2]; local_138 = abStack_137[uVar2]; uVar2 = uVar2 + 1; } while (local_138 != 0); pbVar3 = local_358 + (uVar2 & 0xffffffff); } *pbVar3 = 0; (**(code **)(*param_1 + 0x550))(param_1,param_3,uVar1); (**(code **)(*param_1 + 0x538))(param_1,local_358);}So, uh, yeah that’s definitely code.
This isn’t actually as bad as it looks, at least that’s what I realised after NoSharp explained it to me.
First off, this wizard knew what a .gdt archive was, or a Ghidra Data Type. What these archives do is help Ghidra figure out the structure of datatypes. For example, if you provided a GDT archive
that told Ghidra string types had a function called slice at offset 0x458, it would replace a call such as (*p + 0x458) with (*p->slice()), making the code more readable. Thankfully,
someone had already created a GDT archive for us to use with JNI code.
With that archive imported, we did some googling to find out how JNI functions are written in C++ and quickly found that the first argument of most functions is JNIEnv *param_1, effectively a pointer to a function table.
With the GDT archive, updating the first parameters signature to JNIEnv * should reveal some function calls…
void Java_com_lagoru_jnirealm_HidingUtils_unhide(JNIEnv *param_1,undefined8 param_2,jstring param_3)
{12 collapsed lines
char *chars; ulong uVar1; byte *pbVar2; long in_FS_OFFSET; byte local_358 [272]; byte local_248 [272]; byte local_138; byte abStack_137 [263]; long local_30;
pbVar2 = local_358; local_30 = *(long *)(in_FS_OFFSET + 0x28);
uVar1 = (**(code **)(*param_1 + 0x548))(param_1,param_3,0);
chars = (*(*param_1)->GetStringUTFChars)(param_1,param_3,(jboolean *)0x0);Awesome! Now we have a slightly better idea of what’s going on. Though it didn’t reveal anything too significant, it helps us parse out what is and isn’t useful.
We now went through and started naming variables to make it easier to track what’s going on.
void Java_com_lagoru_jnirealm_HidingUtils_unhide(JNIEnv *param_1,jobject param_2,jstring input)
{ char *chars; ulong counter; byte *pbVar1; long in_FS_OFFSET; byte final_string [272]; byte key_decoded [272]; byte input_decoded; byte abStack_137 [263]; long local_30;
pbVar1 = final_string; local_30 = *(long *)(in_FS_OFFSET + 0x28); chars = (*(*param_1)->GetStringUTFChars)(param_1,input,(jboolean *)0x0); memset(&input_decoded,0,0x101); memset(key_decoded,0,0x101); Base64Decode(chars,&input_decoded,0x100); Base64Decode("...",key_decoded,0x100); memset(final_string,0,0x101); if (input_decoded != 0) { counter = 0; do { final_string[counter] = input_decoded ^ key_decoded[counter]; input_decoded = abStack_137[counter]; counter = counter + 1; } while (input_decoded != 0); pbVar1 = final_string + (counter & 0xffffffff); } *pbVar1 = 0; (*(*param_1)->ReleaseStringUTFChars)(param_1,input,chars); (*(*param_1)->NewStringUTF)(param_1,(char *)final_string);}I’m sure most of us can figure out what’s happening here, the only part we really had to take a second to understand was:
memset(final_string,0,0x101);if (input_decoded != 0) { counter = 0; do { final_string[counter] = input_decoded ^ key_decoded[counter]; input_decoded = abStack_137[counter]; counter = counter + 1; } while (input_decoded != 0); pbVar1 = final_string + (counter & 0xffffffff);}The ^ is the XOR operator in C++. All this code is doing is XOR’ing each character of the input string with the key string. Which means that to get our decryption key we just
need to take the key from the getGeneratedKey function and the key found inside this native library and XOR each character of each.
There’s also the AES256Cipher class that’s used to do the decryption, there’s nothing special in here other than telling us the IV used and AES mode.
public class AES256Cipher { private static final String AES_MODE = "AES/CBC/PKCS5PADDING"; private static final String TAG = "com.stagecoach.core.utils.AES256Cipher"; private static final byte[] ivBytes = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};At this point, we were ready to write a little python script to do this for us.
Decryption Script
import base64from Crypto.Util.Padding import unpadfrom cryptography.hazmat.primitives.ciphers import Cipherfrom cryptography.hazmat.backends import default_backendfrom cryptography.hazmat.primitives.ciphers.algorithms import AESfrom cryptography.hazmat.primitives.ciphers.modes import CBC
encrypted_bytes_list = [...]encrypted_bytes = bytes([byte % 256 for byte in encrypted_bytes_list])
iv = bytes([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
private_key = base64.b64decode('<key-from-ticket-ref-lib>')other_key = base64.b64decode('<key-from-get-generated-key-function>')
key = bytes(a ^ b for a, b in zip(private_key, other_key))
cipher = Cipher(AES(key), mode=CBC(iv), backend=default_backend())result = cipher.decryptor().update(encrypted_bytes)
with open('output', 'w') as out: out.write(unpad(result, 16).decode())Let’s walk through this step by step:
encrypted_bytes_list = [...]encrypted_bytes = bytes([byte % 256 for byte in encrypted_bytes_list])Bytes in Java are signed, meaning a byte can range from -128 to 127. But in python bytes are unsigned, meaning they range from 0 to 255. So the first thing we need to do is convert to bytes from signed to unsigned.
This is what the byte % 256 is doing.
private_key = base64.b64decode('<key-from-ref-ticket-lib>')other_key = base64.b64decode('<key-from-get-generated-key-function>')The keys are base64 encoded strings, so we need to decode them and get the bytes.
key = bytes(a ^ b for a, b in zip(private_key, other_key))This is a fancy way of doing the XOR’ing previously mentioned, so each character in each key is XOR’d to get the real decryption key.
cipher = Cipher(AES(key), mode=CBC(iv), backend=default_backend())result = cipher.decryptor().update(encrypted_bytes)I’m using the cryptography library to do the decryption here.
with open('output', 'w') as out: out.write(unpad(result, 16).decode())Then finally, we need to remove the AES padding, which is 16 bytes per block and then decode the bytes to UTF-8.
aaaaaaannndddd…
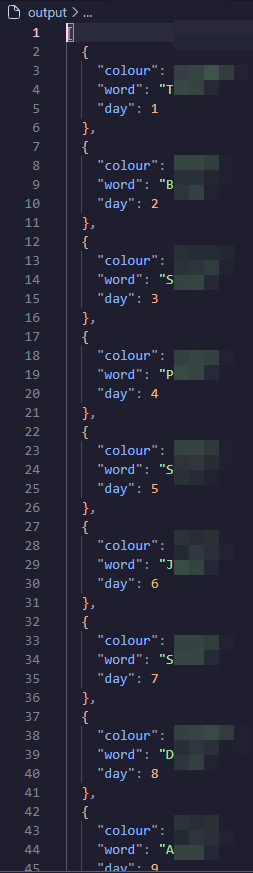
Success! :D
We now have all of the words of the day for the Stagecoach app, seems like they store the entire years worth of words.